@仿生人会梦到电子羊吗Do Androids Laugh at Electric Sheep
摘要
- 大型神经网络现在可以生成笑话,但它们真的“理解”幽默吗?
- 本文使用源自《纽约客》漫画大赛的三个任务来挑战 AI 模型:
- 将笑话与漫画进行匹配。
- 识别获胜的标题。
- 解释为什么获胜的标题很有趣。
- 这些任务需要理解图像和标题之间复杂的关系,包括对人类经验和文化的间接影射。
- 多模态和仅语言模型都在所有三个任务中挣扎。
- 即使提供了真实的视觉场景描述符,在超过 2/3 的情况下,人类创作的解释也比机器创作的解释(少样本 GPT-4)更受欢迎。
- 该论文发布了模型、代码、排行榜和一个语料库,其中包含描述图像位置/实体、不寻常元素和笑话解释的新注释。
1. 介绍
- 幽默可以被解剖,但这个过程可能会具有破坏性。
- 《纽约客》每周都会发布一张没有标题的漫画图像,邀请读者提交标题。编辑选择三个决赛入围者,读者投票选出获胜者。
- 本文开发了三个任务来测试 AI 模型对幽默的理解:
- 将笑话与漫画进行匹配。
- 识别获胜的标题。
- 解释为什么图像/标题组合很有趣。
- 这些任务很困难,因为获胜标题和图像之间的联系可能很微妙,会影射到人类的经验和文化。
- 示例:标题“请把奶牛递过来好吗?”需要识别图像中不寻常的马克杯尺寸,并将其与大量的奶油/牛奶联系起来。
- 模型还应该解释为什么一个高评价的标题很有趣。
- 考虑了两个设置:
- 来自像素(From Pixels): 模型仅获得漫画图像。
- 来自描述(From Description): 模型获得人类创作的漫画描述。
- 考虑了两个设置:
- 结果表明 AI 和人类水平的幽默理解之间存在差距。
- 最佳多模态模型在 5 项选择题任务中实现了 62% 的准确率,而人类实现了 94%。
- 即使经过手动注释,在超过三分之二的情况下,人类解释也比最佳解释模型(少样本 GPT-4)更受欢迎。
2. 数据集和任务设置
- 该语料库汇编了 14 年的《纽约客》漫画大赛,包括:
- 没有标题的漫画。
- 条目。
- 三个决赛入围者。
- 质量估计(对于某些比赛)。
- 该语料库由两个来源构建:
- 删除了 55 场比赛的低分辨率图像,并确定了 80 个低分辨率案例以进行特殊注释。
2.1 任务设置
匹配
- 给出五个选项,其中只有一个对应。
- 否定选项是从其他比赛中随机选择的决赛入围者。
- 标题和图像之间的关系可能是间接的,需要外部知识或推理。
质量排名
- 对于每个决赛入围者,都会抽取一个非决赛入围者的标题进行比较。
- 模型必须识别哪个标题被评为更高质量。
解释
- 形成了 651 个人类创作的笑话解释语料库(平均/中位数 60/59 个单词,总共 39.3K 个)。
- 如果人类评委不喜欢作者生成的解释,则模型成功。
评估指标
- 匹配和质量排名使用准确率进行评估。
- 对于质量排名,报告
NYAcc(官方《纽约客》决赛入围者的准确率)和CrowdAcc(人群选择标题的准确率)。
- 对于质量排名,报告
- 解释使用成对的人工评估进行评估。
- 自动指标(BLEU-4、ROUGE-L、单词级困惑度)也在附录 E 中报告。
2.2 漫画注释
- 收集了 704 幅漫画的几种类型的注释:
- 描述场景设置的短语(每幅漫画 2 个)。
- 场景的 1-3 句文字描述(每幅漫画 3 个)。
- 描述场景不寻常之处的 1-3 句话(每幅漫画 3 个)。
- 2-3 个被识别为相关的英语维基百科链接(每幅漫画 2 个)。
3. 实验
- 704 幅漫画被分成 5 个交叉验证分割,在测试时保留整个比赛。
来自像素(FP)模型
CLIP
- 微调的 CLIP ViT-L/14@366px(Radford 等人,2021 年)(4.28 亿个参数)。
- 由一个文本 Transformer 和一个视觉 Transformer 组成,经过预训练以对齐 WebImageText 语料库(4 亿对)中的图像/标题。
- 使用 InfoNCE 来鼓励漫画/正确答案的余弦相似度高于不正确答案。
- 对于零样本分类,使用提示
a new yorker cartoon with winning caption。 - CLIP 不是生成式的,因此不能用于解释。
OFA→LM
- 使用了 OFA Huge(9.3 亿个参数)(Wang 等人,2022 年),这是一个支持图像/文本输入/输出的 seq2seq 模型。
- 在《纽约客》语料库上进行微调,以将(漫画、提示)→描述映射为四种注释类型。
- OFA 预测的输出以与人类创作的描述相同的格式组织,并传递给语言模型。
来自描述(FD)模型
T5
- 对 T5-Large 和 T5-11B(Raffel 等人,2020 年)进行微调。
- 对于解释,使用温度 1.0 和核采样 p=.95(Holtzman 等人,2020 年)进行采样。
GPT-3、GPT-3.5、GPT-4
- 这三个 OpenAI 模型被用作零样本和少样本模型。
- 为模型提供了任务描述,并在少样本情况下提供了 5 个随机标记的上下文示例。
- 对于零样本 GPT-3.5/GPT-4,使用链式思考(CoT)提示。
基线
仅标题
- 仅在标题的情况下微调 T5-11B,而不知道漫画。
人类表现估计
- 三个人尝试了来自匹配和质量排名任务的 100 个随机抽样实例。
- 注释者可以访问图像,但不能访问描述。
硬件 + 软件细节
- T5、CLIP 和 OFA 是使用 pytorch 中的 8 个 A100 GPU 进行训练的。
- 使用 T5 的 Transformers 实现。
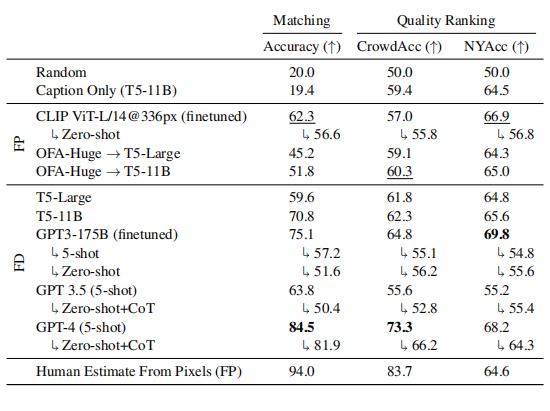
3.1 匹配和质量排名结果
- 来自描述模型
- GPT-4(少样本)通常表现最佳,在匹配方面实现了 84.5% 的准确率。
- GPT-3 和 GPT-4 在预测《纽约客》编辑选择方面优于三个人类,但在预测众包选择方面表现不佳。
- 来自像素模型与人类表现估计相比留下了显著的提升空间。
3.2 解释的人工评估
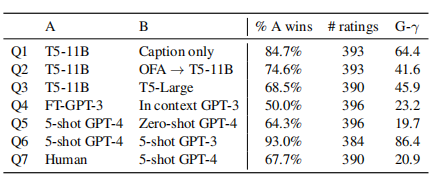
- 从每个测试实例的 3 个众包工作者那里收集判断,并进行多数投票以确定获胜者。
Q1:模型是否利用标题的图像上下文来生成更好的解释?
- 测试:T5-11B 与仅标题的 T5-11B。
- 答案:是的。具有图像信息的模型在 84.7% 的情况下获胜。
Q2:计算机视觉是高质量解释生成的瓶颈吗?
- 测试:T5-11B(FD)与 OFA→T5-11B。
- 答案:是的。使用 OFA 预测训练的模型在 74.6% 的情况下失败。
Q3:更大的 T5 模型是否会生成更好的解释?
- 测试:T5-11B 与 T5-Large。
- 答案:是的。在 68.5% 的情况下,首选 T5-11B。
Q4:对于解释生成,微调 LLM 模型是否有助于与上下文学习相比?
- 测试:FT-GPT3 与上下文(=5-shot)GPT3。
- 答案:不完全是。上下文解释生成与微调的解释生成相当。
Q5:即使使用 GPT-4,监督解释是否有帮助?
- 测试:5-shot GPT-4 与 Zero-shot GPT-4。
- 答案:是的。在 64% 的情况下,首选 5-shot GPT-4。
Q6:GPT-4 是否优于 GPT-3?
- 测试:5-shot GPT-4 与 5-shot GPT-3。
- 答案:是的,当然。在 93% 的情况下,首选 GPT-4 的解释。
Q7:我们最好的模型 GPT-4 是否能像人类一样解释笑话?
- 测试:人类与少样本 GPT-4。
- 答案:否。注释者在 68% 的成对情况下更喜欢人类编写的解释。
3.3 匹配的错误分析
- CLIP ViT-L/14@336px(微调)和 GPT3-175B(微调)的错误分析。
Q8:有些比赛是否比其他比赛更难?
- 答案:是的。错误根据比赛进行聚类(对于 CLIP 和 GPT-3,p < 0.05)。
4. 相关工作
幽默
- Raskin(1979 年)和 Attardo(2008 年)强调了幽默理论的三个“伟大类别”:
- 敌意。
- 约束的释放。
- 不协调。
- Shahaf 等人(2015 年)指出,大多数《纽约客》漫画大赛的漫画都涉及不协调的情况。
NLP + 标题大赛
- King 等人(2013 年)、Shahaf 等人(2015 年)和 Radev 等人(2016 年)分析了《纽约客》标题大赛。
- 表现最佳的特征包括困惑度、与图像设置和怪异描述的匹配、可读性、专有名词、与 WordNet 的“人”和“亲属”同义词集的重叠、词汇中心性和情感。
- 本文通过以下方式扩展了先前的工作:
- 添加两个新颖的任务。
- 使用新的数据/资源/模型来策划排名对。
- 评估两种不同的受众偏好:《纽约客》编辑与“大众”。
衡量标题的偏好
- Tanczos 等人(2017 年)设计了标题大赛的质量排名算法,将其框架为识别多臂老虎机设置中的最佳“臂”。
多模态和计算幽默
- Chandrasekaran 等人(2016 年)探索了图像中的幽默识别。
- Castro 等人(2019 年);Hasan 等人(2019 年);Patro 等人(2021 年);Hasan 等人(2021 年)探索了 TED 演讲/情景喜剧中的笑声预测。
- Tsakona(2009 年);Fallianda 等人(2018 年)研究了政治漫画。
- Chakrabarty 等人(2022 年)最近提出了一个用于比喻语言的 NLI 版本。
- 一些工作试图检测一个句子是否幽默(Blinov 等人,2019 年;Annamoradnejad 和 Zoghi,2020 年)。
解释幽默
- 在 Tan(2022 年)的分类法中,笑话解释与近端机制最相关。
- Chowdhery 等人(2022 年)对(非视觉)笑话解释进行了定性探索。
5. 结论
- 今天的视觉和语言模型无法像人类那样有效地识别标题相关性、评估(重现众包排名)或解释《纽约客》标题大赛。
- 今天的 AI 具有显着的部分能力,足以用于创意合作者,例如头脑风暴助手。
- 匹配/质量排名模型可以帮助参赛者获得有关其提交的相关性/预测质量的定量反馈。
- 注释语料库+解释可以重新用于生成。
- 未来的工作可以将匹配/排名模型提供的反馈在来自人类反馈的强化学习(RLHF)循环中进行操作。
6. 局限性
- 《纽约客》漫画标题大赛代表了幽默的一个狭窄切面。
- 质量排名任务的框架可以被解释为表面上具有规定性,但《纽约客》的编辑选择不应被视为有趣性的事实依据
- 注释语料库中的解释主要由一位作者编写。忽略了人与人之间的差异